前言
’’’
作者: hon20002000
最後更新: 2019/9/20
‘’’
本教程是為了讓同學們快速體驗機器學習/深度學習而設計的.
學習本教程須先了解python基本語法, 例如list, dict, numpy切片等等.
教程用法:
閱讀本blog上的基礎語法
完成每篇文章的作業
部分學習所需的檔案在github下載
遇到問題或其他改善建議可在下面留言
正文
在使用CNN進行我們的比賽之前,我們先學習mnist數據集
mnist含有60,000張28x28像素的人手寫的0~9數字圖像
它是可以直接在spyder下載的
我們的目標就是利用神經網絡neural network來分辨數字
概念流程:
(1)load_data #下載數據集
(2)reshape data #把28x28像素的數據變成784x1像素的數據
因為neural network需要這種shape的數據形式來學習
(3)把label由0~9變為二進制的one-hot編碼, 例如
0 =[1,0,0,0,0,0,0,0,0,0], 3 =[0,0,0,1,0,0,0,0,0,0]
(4)建立及訓練模型:
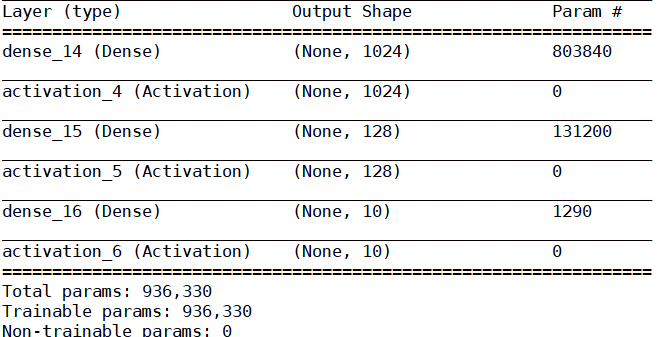
model.Sequential > models.Dense > layers.Activation > model.summary > model.compile > model.fit
下面是完整程式碼:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
#使用keras作為我們的語法並import有用的function
import keras
from keras import models, layers
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, LeakyReLU, Conv2D
from keras.optimizers import RMSprop #optimizer可選擇rmsprop, adadelta, adam, sgd
from keras import backend as K
from matplotlib.pyplot import imshow #顯示圖片的function
import numpy as np #運算工具
# loading train and test sets and reshape
(x_train, y_train), (x_test, y_test) = mnist.load_data() #讀取data
x_train = x_train.reshape(60000, 784) #x=data, y=label, reshape (28x28) -> (784,)
x_test = x_test.reshape(10000, 784) #60000 training data, 10000 test data
x_train = x_train.astype('float32') #由於像數值為0~255的整數, 把它轉為float作計算
x_test = x_test.astype('float32')
x_train /= 255 #把0~255/255即是把數字轉為0~1, 意義是運算的數值變小
x_test /= 255
num_classes = 10
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes) #把數字由0~9轉為one-hot編碼
y_test = keras.utils.to_categorical(y_test, num_classes)
model = models.Sequential()
model.add(layers.Dense(1024, input_shape=(784,))) #first layer need to input data shape
model.add(layers.Activation("relu")) #neural network一般使用relu
model.add(layers.Dense(128)) #dense(128) include 128 parameters in a layer
model.add(layers.Activation("relu"))
model.add(layers.Dense(10)) #最後一層等於分類數目
model.add(layers.Activation("softmax")) #最後一層使用softmax
model.summary()
model.compile(loss='categorical_crossentropy', #多分類使用categorical_crossentropy
optimizer='rmsprop', #optimizer一般有adam, adadelta, rmsprop, sgd等等
metrics=['accuracy'])
batch_size = 128 #batch_size越大每次訓練的數據越多, 注意記憶體可能會不夠用
num_classes = 10
epochs = 10 #重覆訓練10輪
history = model.fit(x_train, y_train, #model.fit才是正式訓練模型, 上面只是設定model
batch_size=batch_size,
epochs=epochs,
verbose=1, #verbose=1表示顯示進度條, 共有0,1,2三種模式
validation_data=(x_test, y_test))
下面詳細講解這段程式碼
首先要有的概念就是,我們將要處理的數據的shape是怎樣的?
我們使用的model能接受的shape又是什麼?
只要這兩個shape是符合的, 那才能訓練model
另外, label是數字或是one-hot是自行決定的, 一般慣例轉換成one-hot編碼
模型的層數是隨意的, 激活函數activation是relu
這些都可以隨意設計
最後一層是分類的數目, 使用激活函數softmax
softmax的特點是所有類別的結果加起來等於100%
所以用來判斷各類別旳機率
我們先看看mnist的一個data是怎樣的數據
在(x_train, y_train), (x_test, y_test) = mnist.load_data()下面加上
1
2
3
4
5
6
7
8
(x_train, y_train), (x_test, y_test) = mnist.load_data() #下載mnist數據集
imshow(x_train[0], cmap='gray') #cv2中用來顯示灰色圖片的語法
print("x_train.shape:", x_train.shape) #所有data的shape
print("x_train[0].shape:", x_train[0].shape) #第一個data的shape
print("y_train.shape:", y_train.shape) #training data的label的shape
print("y_test.shape:", y_test.shape) #test data的label的shape
print("y_train:", y_train) #training data的label
print("y_test:", y_test) #testing data的label
可觀察到如下的結果:
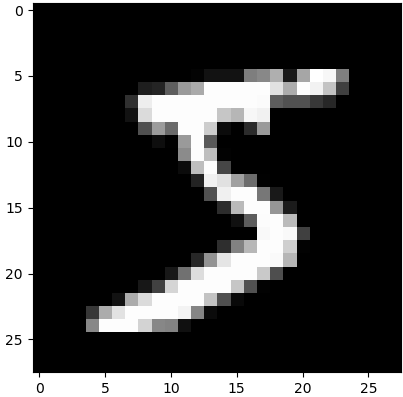 x_train.shape: (60000, 28, 28) #表示這是60,000張相片, 2828像素
x_train.shape: (60000, 28, 28) #表示這是60,000張相片, 2828像素
x_train[0].shape: (28, 28) #第一張相片, 2828像素
y_train.shape: (60000,) #60000個label
y_test.shape: (10000,) #10000個label
y_train: [5 0 4 … 5 6 8] #training data的label
y_test: [7 2 1 … 4 5 6] #testing data的label
然後我們在one-hot編碼前後加入print(“y_train[0]:”, y_train[0])
觀察label的變化, 加入後會是這樣的代碼
1
2
3
4
print("y_train[0]:", y_train[0]) #原始的label
y_train = keras.utils.to_categorical(y_train, num_classes) #one-hot後的label
y_test = keras.utils.to_categorical(y_test, num_classes) #one-hot後的label
print("y_train[0]:", y_train[0])
會觀察到:
y_train[0]: 5 #原始的label
y_train[0]: [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.] #one-hot後的label
建立的model結構:
最後我們觀察一下訓練結果:
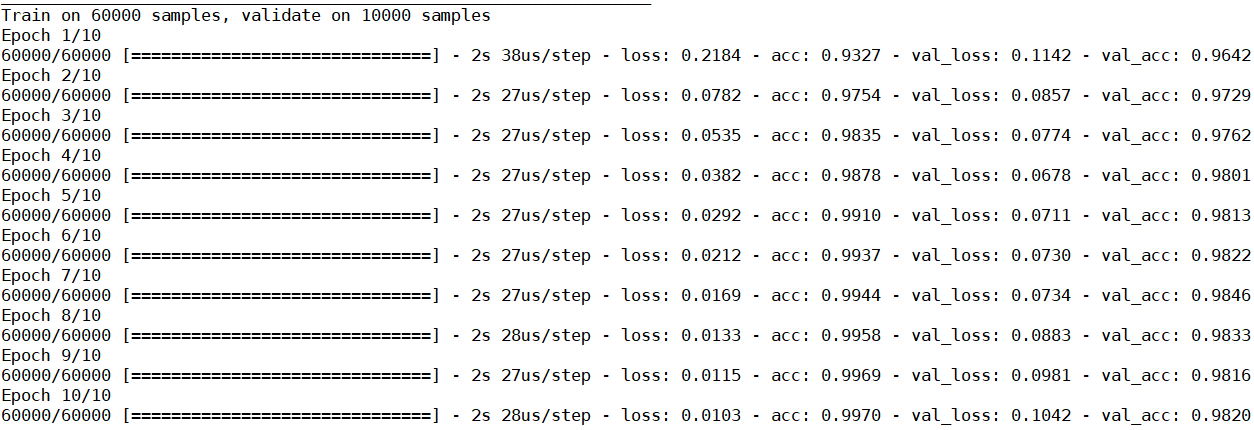
loss是指training的誤差, val_loss是把training後的model應用在驗證集上的誤差
acc是training的準確率, val_acc是應用在驗證集上的準確率
簡單而言, loss和val_loss都是越低越好, 但若果loss在下降而val_loss在上升
或者是val_loss和loss之間的差距開始變大, 這是過擬合的訊號
這時訓練該停止了
acc一般沒有太大用途, 因為只要過擬合, 基本上都能達到90~100%的準確率
而val_acc則比較重要, 它說明一個model在不同的數據集是否仍然保持高的準確率
本實驗結果顯示, 我們利用 1024 –> 128 –> 10 這樣的結構
已經基本能把手寫數字辨識出來(98%+)
但最後要說明的是, 一般數據集應該要分為3個而不是2個
即數據集要分為1) training data, 2) validation data, 3) test data
為什麼數據集只切分為1和2是不完善呢?是因為在訓練過程中, 我們會不斷的調節參數
令validation和training的準確率最大化, 但實際上這是一種假像
因為model要預測的真實圖片是未知的, 但training data和validation data是已知的
通過不斷的重覆學習, 並不能說明model在預測未知圖片是準確的
因此必須使用不參與訓練的test data作為最後的評估
練習
(1)把程序重頭到尾手動輸入一次, 看看是否真懂得每句代碼的意思
(2)把num_class, batch_size, epochs的數值改變, 看看結果和運行時間怎樣改變
(3)把optimizer改為其他, 看看在相同條件下哪一個更佳?
(4)改變layers的結構, 例如128x128x128…. -> 10?
(5)把accuracy提升到99%?
—