前言
’’’
作者: hon20002000
最後更新: 2019/9/21
‘’’
本教程是為了讓同學們快速體驗機器學習/深度學習而設計的.
學習本教程須先了解python基本語法, 例如list, dict, numpy切片等等.
教程用法:
閱讀本blog上的基礎語法
完成每篇文章的作業
部分學習所需的檔案在github下載
遇到問題或其他改善建議可在下面留言
正文
本次使用cifar10作為我們的練習素材並學習一些新的語法
cifar10是把日常生活中的10種物件分類, 是32x32x3的彩色圖片

32x32是圖片的width和height, 3是指RGB的數值
實際圖片的數據是R:32x32, G:32x32, B:32x32
這是和mnist黑白圖片最大的不同
前一節說過neural network, data的shape和model的shape要匹配
所以把(32x32x3) reshape 成(3072,)才能訓練
而CNN則不需要reshape
我們用neural network(NN)和convolutional neural network(CNN)來作比較
看看訓練結果差異多少
NN概念流程:
(1)load_data #下載數據集
(2)reshape data #把32x32x3數據變成3072x1
(3)把label由0~9變為二進制的one-hot編碼
(4)建立模型 model.Sequential() > models.Dense > layers.Activation > model.summary > model.compile > model.fit
CNN概念流程:
(1)load_data #下載數據集
(2)把label由0~9變為二進制的one-hot編碼
(3)建立模型 model.Sequential() > models.Conv2D > models.flatten > models.Dense > layers.Activation > model.summary > model.compile > model.fit
下面是完整程式碼:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
#使用keras作為我們的語法並import有用的function
import keras
from keras import models, layers
from keras.datasets import cifar10
from keras.models import Sequential
from keras import layers, models, optimizers
from keras.layers import Dense, Dropout, LeakyReLU, Conv2D, Activation
from keras.optimizers import RMSprop
from keras import backend as K
from matplotlib.pyplot import imshow
import numpy as np
# the data, shuffled and split between train and test sets
(x_train, y_train), (x_test, y_test) = cifar10.load_data() #下載cifar10數據集
#imshow(x_train[0], cmap='gray') #顯示灰色圖片
#imshow(x_train[0]) #顯示彩色圖片
#print("x_train.shape:", x_train.shape) #(50000, 32, 32, 3)
#print("x_train[0].shape:", x_train[0].shape) #(32, 32, 3)
#print("y_train.shape:", y_train.shape) #(50000, 1)
#print("y_test.shape:", y_test.shape) #(10000, 1)
x_train = x_train.reshape(50000, 3072) #32x32x3 =3072
x_test = x_test.reshape(10000, 3072)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
num_classes = 10
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = models.Sequential()
model.add(layers.Dense(1024, input_shape=(3072,)))
model.add(layers.Activation("relu"))
model.add(layers.Dense(512))
model.add(layers.Activation("relu"))
model.add(layers.Dense(10))
model.add(layers.Activation("softmax"))
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
batch_size = 128
num_classes = 10
epochs = 10
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
結果如下:

使用CNN作訓練:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
'''使用keras作為我們的語法並import有用的function'''
import keras
from keras import models, layers
from keras.datasets import mnist
from keras.datasets import cifar10
from keras.models import Sequential
from keras import layers, models, optimizers
from keras.layers import Dense, Dropout, Conv2D, Activation, MaxPooling2D
from keras.optimizers import RMSprop
from keras import backend as K
from matplotlib.pyplot import imshow
import numpy as np
import time
import pandas as pd
from keras.callbacks import CSVLogger
np.random.seed(1671) # for reproducibility, 數字是多少不重要
month = time.localtime().tm_mon
day = time.localtime().tm_mday
hour = time.localtime().tm_hour
mins= time.localtime().tm_min
date = str(month)+"_" + str(day)+"_" + str(hour)+"_" + str(mins) #記錄時間
# the data, shuffled and split between train and test sets
(x_train, y_train), (x_test, y_test) = cifar10.load_data() #下載cifar10數據集
imshow(x_train[1])
print("x_train.shape:", x_train.shape)
print("x_train[0].shape:", x_train[0].shape)
print("y_train.shape:", y_train.shape)
print("y_test.shape:", y_test.shape)
print("y_train:", y_train)
print("y_test:", y_test)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
num_classes = 10
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = models.Sequential()
# CONV => RELU => POOL
model.add(layers.Conv2D(32, (3, 3), input_shape=(32, 32, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(3, 3)))
# CONV => RELU => POOL
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
# Flatten => RELU
model.add(layers.Flatten())
model.add(layers.Activation("relu"))
model.add(layers.Dropout(0.4))
# Dense => RELU
model.add(layers.Dense(1024))
model.add(layers.Activation("relu"))
model.add(layers.Dense(512))
model.add(layers.Activation("relu"))
model.add(layers.Dense(10))
model.add(layers.Activation("softmax"))
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
batch_size = 128
num_classes = 10
epochs = 10
csv_logger = CSVLogger('cifar10'+'_'+date+'.csv', append=True, separator=',') #使用','作分隔
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test),
callbacks=[csv_logger]) #加上callbacks在model.fit中
結果如下:
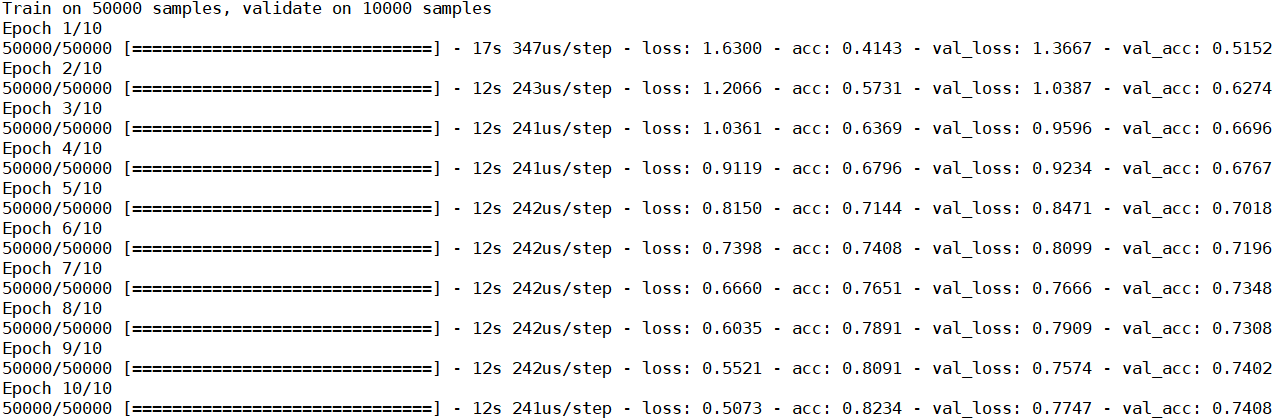
可以看出CNN第1輪訓練已有51.52%, 比起NN的第10輪46.72%要高
使用CNN可以輕易把mnist訓練至超過99.0%
CNN是訓練圖像的首選方法, 因為CNN不會把圖像reshape
可以保留每個像素之間的關係, 而NN則需要reshape
明顯地圖像的資訊已被扭曲, 是強行訓練出結果的
其他機器學習方法在圖像分析準確度也不好
另外我們使用CSVLogger來儲存訓練結果
把一些訓練數據記錄能方便我們調節參數及製作報告
練習
(1)把程序重頭到尾手動輸入一次, 看看是否真懂得每句代碼的意思
(2)把num_class, batch_size, epochs的數值改變, 看看結果和運行時間怎樣改變
(3)把optimizer改為其他, 看看在相同條件下哪一個更佳?
(4)改變layers的結構, 把accuracy提升到80%?
—