前言
’’’
作者: hon20002000
最後更新: 2019/9/21
‘’’
本教程是為了讓同學們快速體驗機器學習/深度學習而設計的.
學習本教程須先了解python基本語法, 例如list, dict, numpy切片等等.
教程用法:
閱讀本blog上的基礎語法
完成每篇文章的作業
部分學習所需的檔案在github下載
遇到問題或其他改善建議可在下面留言
正文
本節總結比賽開始到現在(second stage)的技術發展過程
(1)比賽單位使用csv檔記錄圖片名稱來制作label, 我們改為使用file名稱制作label
省去了輸入資料的麻煩及方便管理圖片
我們統一拍攝1:1的正方形相片及resize成為150像素的圖片
大會使用的舊方法:
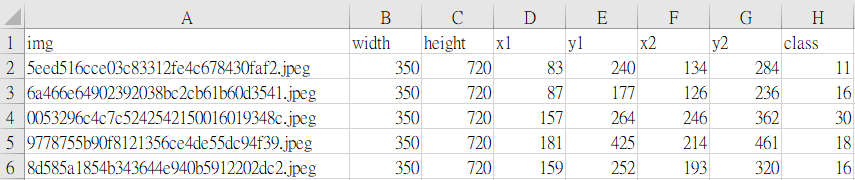
我們使用的新方法:


(2)比賽的signs總共有120種, 其中約40種無法在現實生活中找到
例如:
 因此我們決定利用photoshop p圖來制作擬真的相片來收集數據
因此我們決定利用photoshop p圖來制作擬真的相片來收集數據
最初的圖像是這樣的:

我們利用在街上拍攝的真實路標圖片作test data時
發現分辨率很低
經過多次優化圖片, 放大縮小, 旋轉路牌, 偏移等
最終分辨率還是只有不到60%, 因此我們放棄了p圖這種方法
最後我們把路標列印出來制作道具, 進行模擬拍攝
發現這種道具的分辨率極高, 和真實圖片的效果幾乎相同
最終拍攝的圖片是這樣的:

真實圖片是這樣的:

這樣我們可以在3-5分鐘之內收集到一種sign約300張圖片
一小時內可收集4000張相片, 並且我們已經擁有所有的sign!
若在大街上拍攝, 平均每小時只能拍攝不到1000張相片
並且很多sign是找不到的!
(3)我們使用數據增強(ImageDataGenerator)來增加相片集:
數據增強是一種能改變圖片的function
合理使用能使相片集增加數倍~數十倍數據
常用可選擇的參數有:
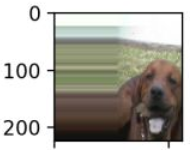
(1)zca_whtening: zca白化可以減少圖片的冗餘訊息, 保留最重要的資訊
這裡我沒有圖片, 我在網上找了一張白化後的圖片:

(2)rotation range: 在指定角度內隨機旋轉, 符合真實拍攝情況
(3)width_shift_range & height_shift_range: 圖片拉伸
由於拉伸後的圖片變得很怪異, 並且可能把重要的圖示移出範圍外, 不適合
(4)shear_range: 圖片在指定角度內隨機傾斜, 符合真實拍攝情況
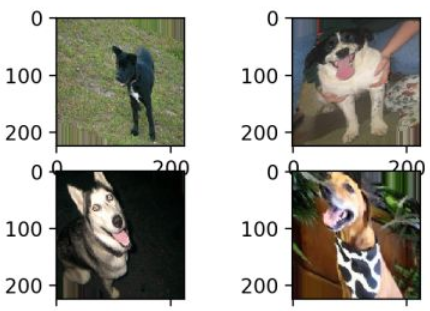
(5)zoom_range: 圖片在指定範圍內隨機放大(參數0<x<1)及縮小(x>1)
可以使用放大的功能, 但縮小時的圖很怪異, 不適合
(6)channel_shift_range: 改變圖片的顏色, 符合真實拍攝情況
(7)horizontal_flip & vertical_flip: 水平翻轉及垂直翻轉, 由於路標在翻轉後意義會改變, 因為不適合
(8)rescale: 把圖片的像素值由0~255變為0~1, 但由於我們在model中已使用batch_normalization(也是轉為0~1)
因此這個rescale可加可不加, 有空可嘗試結果有沒有變化, 但必需同時把test_data的photo rescale
否則會完全分辨不到
綜上所述, 最終應用的數據增強是: 1, 2, 4, 5, 6
(4)生成器(generator):
生成器是一種語法, 讀取數據分兩種方法, 一種是把資料在開始前完全讀取進內存中
另一種是部分讀取, 使用完後再讀取新的一批資料, 這樣對內存的壓力會減少
由於相片集太大, 若按照一般流程把全部資料讀進至內存後再訓練會死機
因此我們使用生成器來讀取資料, 我們先讀取所有圖片的地址(不是圖片資料)
然後再一批批的讀取圖片資料, 訓練完一批後再讀取下一批
因此內存不會OOM(out of memory)
使用生成器後我們能訓練的相片限制由原來的4萬張變為可以處理超過10萬張相片
(5)model:
由於MacauAI的檔案上傳限制約在500mb左右, 因此我們要在有限的層數上做到最準確的模型
現時最終的模型是:
Conv(32)->Conv(64)->Conv(128)->Conv(192)->
Flatten()->Dense(1536)->Dense(1024)->Dense(121)
中間使用了BatchNormalization, Dropout及MaxPooling
根據書本上的經驗參數, BN幾乎每一層都使用
而Dropout=0.2~0.5, 只用在Dense層
當然這不一定是最優化, 但可供參考
現時自己製作的test_data有約75~80%的準確率
在比賽的測試集上平均達到87~91%的準確率
自己準備的test_data較低是因為我們拍攝了很多夜間及不是標準的路標
簡單地講, 我們的test_data比比賽的test_data要困難

(6)多種model協作(已放棄):
在初期我們曾經嘗試使用多個model來協同分辨圖片, 看看能否比單一model更有效
因為一個model分開5種類別比要分辨120種簡單很多
我們把120種signs分為5大類型:

然後我們再獨立訓練5個model來分辨此5個子集
那麼class的數目複雜度便可以由120種縮小為20~40種
若model能很好地區分此5種類型(約96~97%)
那麼最終結果應該有明顯提升的
不過由於model大小的限制(500mb), 我們放棄了使用多model分類的方法
(7)一張相片內切割多個小區作分類(正在嘗試):
由於upload file 500mb的限制, 我們改變策略, 使用1個model但把相片切割成多張子相片
若一張圖片中在拍攝時有較多背景, 例如:

若然我們對圖片先進行放大至170x170, 那麼我們在其中切割出150x150的數張圖片
例如下圖中的4個角位及中央圖片,再加上原圖, 那麼這6張圖片的result應該是相同的(這是label.1)
可以看出當圖片在中央而且較小時, 這種方法明顯地可把路標放大
同時去除不必要的背景, 這種情況肯定可以提升效能

若圖片較大時, 切割也沒有影響
 若圖片較小且偏向角位時, 部分切割有影響(切到圖標), 但部分切割有變好
若圖片較小且偏向角位時, 部分切割有影響(切到圖標), 但部分切割有變好

此種方法現時仍在實驗階段, 使用test_data作實驗時
分辨率有時變高, 有時變低
總括來說, 在比賽中是有用的(因為比賽只計算最高成績)
練習
(1)了解何謂數據增強(ImageDataGenerator)
(2)了解生成器(generator)
(3)了解較簡單的CNN技術, 例如LeNet, AlexNet, VGG16等等
—