前言
’’’
作者: hon20002000
最後更新: 2019/9/22
‘’’
本教程是為了讓同學們快速體驗機器學習/深度學習而設計的.
學習本教程須先了解python基本語法, 例如list, dict, numpy切片等等.
教程用法:
閱讀本blog上的基礎語法
完成每篇文章的作業
部分學習所需的檔案在github下載
遇到問題或其他改善建議可在下面留言
正文
本節介紹我們訓練model的py檔 - CNN_for_submit_generator.py
這個檔案經常更新, 所以最終版本和這個可能有少許出入
概念流程:
(1)import module
(2)define function #定義所有函數
(3)get date & time #讀取時間, 存檔時的名稱
(4)prepare_list_and_dict & prepare_data #讀取出資料
(5)one-hot #把label轉成one-hot
(6)CNN model #建立model架構
(7)ImageDataGenerator #數據增強, zca白化, 偏移, 旋轉等
(8)generator #分批讀取數據
(9)model.fit_generator #訓練model
(10)model.history #輸出訓練result
(11)model.save
(12)model.evaluate #在training data分割一部分作為test_data作評估
(13)plt.plot
下面給出所有的程式碼:
實踐時只需複製所有的程式碼, 並且安裝好必須的module
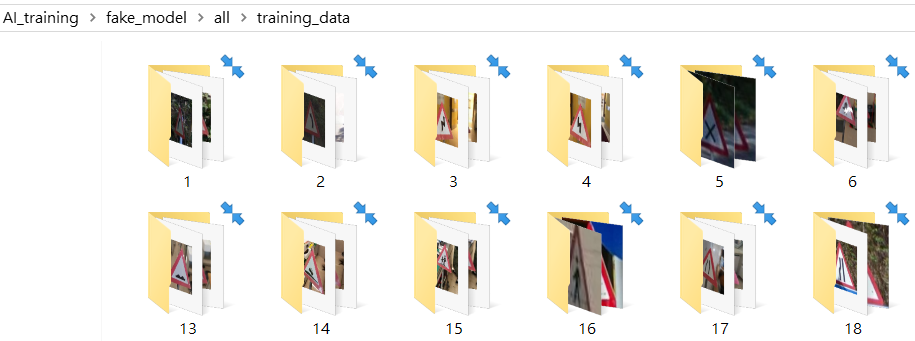
training_data裡面含有命名為1~120的file
不需要全部120種file也可以, 裡面隨意放入20-30張相片作訓練
相片太多沒有gpu是運行不了的, 因此只需少量相片便可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
'''
1. import modele
2. defint function
3. get date & time
4. prepare data & label
5. train_val_test_split, train:val:test = 3:1:1
6. one-hot
7. CNN model
8. ImageDataGenerator
9. prepare data by generator
10. model.fit_generator
11. model.save
12. model.evaluate
13. plt.plot
'''
'''----------import module----------'''
import os, cv2, random
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
from keras.preprocessing.image import img_to_array, load_img,array_to_img
from keras import layers, models, optimizers
from keras import backend as K
from keras.utils import np_utils
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from keras.layers import Conv2D, Activation, Dropout, MaxPooling2D, MaxPool2D, Flatten, Dense, BatchNormalization
from keras.models import Sequential
import matplotlib.pyplot as plt
from keras.models import load_model
#import h5py
#from sklearn.preprocessing import LabelBinarizer
import time
import pandas as pd
from keras.callbacks import CSVLogger
#from quiver_engine import server
'''----------prepare data, label and generator----------'''
def prepare_list_and_dict(img_path):
dict_to_save = {}
img_list = []
path = img_path
files = os.listdir(path) #files = ['0']
#print(files)
for file in files:
filepath = path+ "/" + file #filepath = ['signs_test2_split//1','...','...']
#print("filepath:", filepath)
filenames = os.listdir(filepath) #filenames = ['1','2','3',...'120']
#print("filenames:", filenames)
for filename in filenames:
img_filename = filepath + "/" + filename
#print("img_filenames:", img_filename)
img_paths = os.listdir(img_filename)
#print("img_paths:", img_paths) #img_paths: ['IMG_20190719_123338.jpg'...]
for img_path in img_paths:
pic_path = img_filename + "/" + img_path
img_name = pic_path # dict: {'signs_test2_split/3/85/abc.jpg: 1'}
img_label = int(filename) #(choose label = file or filename) (label = name -1) eg. 1->0, 39->38
img_list.append(img_name)
dict_to_save[img_name] = img_label
#print("dict_to_save:", dict_to_save)
return img_list, dict_to_save
def prepare_data(img_list, dict_names):
x = [] # images as arrays
y = [] # labels
img_width = 150
img_height = 150
for image in img_list: #cv2.imread(image)是用cv2讀取圖片, image是路徑, 返回一串data, 以list形式儲存在x中
try:
x.append(cv2.resize(cv2.imread(image), (img_width, img_height), interpolation=cv2.INTER_CUBIC))
label = int(dict_names[image])
y.append(label)
except:
pass
return x, y
def data_generator(data, targets, batch_size): #x=np.array(x_train), y=y_train
batches = (len(data) + batch_size - 1)//batch_size #假設len=100, batch=10, (100+10-1)//10 = 10
while(True):
for i in range(batches): #把data分成n=batches份區間
X = data[i*batch_size : (i+1)*batch_size] #每一區間內的data讀取
Y = targets[i*batch_size : (i+1)*batch_size] #每一區間內的label讀取
yield (X, Y)
def val_generator(data, targets, batch_size):
batches = (len(data) + batch_size - 1)//batch_size
while(True):
for i in range(batches):
X = data[i*batch_size : (i+1)*batch_size]
Y = targets[i*batch_size : (i+1)*batch_size]
yield (X, Y)
'''----------get date & time----------'''
np.random.seed(1671) # for reproducibility
t0 = time.time()
month = time.localtime().tm_mon
day = time.localtime().tm_mday
hour = time.localtime().tm_hour
mins= time.localtime().tm_min
date = str(month)+"_" + str(day)+"_" + str(hour)+"_" + str(mins)
'''----------prepare_list_and_dict & prepare_data----------'''
path = 'all_correction'
img_list, dict_to_save = prepare_list_and_dict(path)
x, y = prepare_data(img_list, dict_to_save)
'''train_test_split, train:val:test = 3:1:1'''
x_mid, x_val, y_mid, y_val = train_test_split(x,y, test_size=0.2) #mid:val = 4:1
x_train,x_test,y_train,y_test = train_test_split(x_mid,y_mid,test_size=0.25) #train:test = 3:1
'''----------one-hot----------'''
classes = 121
y_train = np_utils.to_categorical(y_train, num_classes = classes)
y_val = np_utils.to_categorical(y_val, num_classes = classes)
y_test = np_utils.to_categorical(y_test, num_classes = classes)
t1 = time.time()
prepare_time = t1 - t0
print("Time to prepare data: {:.2f} seconds ...".format(prepare_time))
nb_train_samples = len(x_train)
nb_validation_samples = len(x_val)
batch_size = 128
epochs = 40
'''----------CNN model----------'''
model = models.Sequential()
chanDim = -1
# CONV => RELU => POOL
model.add(layers.Conv2D(32, (3, 3), input_shape=(150, 150, 3)))
model.add(BatchNormalization(axis=chanDim))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(3, 3)))
# (CONV => RELU) * 2 => POOL
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(BatchNormalization(axis=chanDim))
model.add(Activation("relu"))
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(BatchNormalization(axis=chanDim))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
# (CONV => RELU) * 2 => POOL
model.add(layers.Conv2D(192, (3, 3), padding="same"))
model.add(BatchNormalization(axis=chanDim))
model.add(layers.Activation("relu"))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
# first (and only) set of FC => RELU layers
model.add(layers.Flatten())
model.add(BatchNormalization(axis=chanDim))
model.add(layers.Activation("relu"))
model.add(layers.Dropout(0.3))
model.add(layers.Dense(1536))
model.add(BatchNormalization(axis=chanDim))
model.add(layers.Activation("relu"))
model.add(layers.Dropout(0.3))
model.add(layers.Dense(1024))
model.add(BatchNormalization(axis=chanDim))
model.add(layers.Activation("relu"))
model.add(layers.Dropout(0.25))
# softmax classifier
model.add(layers.Dense(classes))
model.add(layers.Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adadelta', #rmsprop, adam, momentum, adagrad, adadelta
metrics=['accuracy'])
model.summary()
'''----------ImageDataGenerator----------'''
train_datagen = ImageDataGenerator(
zca_whitening=True,
#rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
channel_shift_range=10,
horizontal_flip=False)
val_datagen = ImageDataGenerator(
zca_whitening=True,
#rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
channel_shift_range=10,
horizontal_flip=False)
'''----------old_generator----------'''
#train_generator = train_datagen.flow(np.array(x_train), y_train, batch_size=batch_size)
#validation_generator = val_datagen.flow(np.array(x_val), y_val, batch_size=batch_size)
'''----------new_generator----------'''
train_generator = data_generator(np.array(x_train), y_train, batch_size=batch_size) #讀取batch_size那麼多的data
validation_generator = val_generator(np.array(x_val), y_val, batch_size=batch_size)
csv_logger = CSVLogger(date+'.csv', append=True, separator=',') #csv必須以','分隔
'''----------model.fit_generator----------'''
visualize_acc_loss = model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size,
callbacks=[csv_logger]) #callbacks可以建立csv檔
'''----------model.fit_generator會記錄record, 可通過.history / .epoch來查詢
類似地可用.histroy['val_loss'], .histroy['loss'], .histroy['val_acc'], .histroy['acc'])
----------'''
print("history:", (visualize_acc_loss.history['acc'])) #history['acc']記錄了10次結果
print("epoch:", visualize_acc_loss.epoch) #epoch是從0-9共10次
print("accuracy: {:.2f}%".format(visualize_acc_loss.history['acc'][-1]*100))
print("epoch:", visualize_acc_loss.epoch[-1]+1)
'''----------model.save----------'''
result = "{:.0f}".format(visualize_acc_loss.history['acc'][-1]*100000)
CNN = 'CNN_for_submit'
save_path_h5 = 'sign'+result+'.h5'
save_path_png = 'sign'+result+'.png'
model.save(CNN+'_'+date+'_'+save_path_h5)
'''----------model.evaluate----------'''
t2 = time.time()
training_time = t2 - t1
print("Training time: {:.2f} seconds ...".format(training_time))
predict = model.evaluate(np.array(x_test), y = y_test, batch_size=32, verbose=1)
print("'predict:", predict)
plt.style.use("ggplot")
plt.figure()
N = EPOCHS = epochs
plt.plot(np.arange(0, N), visualize_acc_loss.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), visualize_acc_loss.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), visualize_acc_loss.history["acc"], label="train_acc")
plt.plot(np.arange(0, N), visualize_acc_loss.history["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.xlim((0, epochs))
plt.ylim((0, 1))
plt.legend(loc="upper left")
plt.savefig(CNN+'_'+date+'_'+save_path_png)
==========================ONE==========================
這裡把上面的程式碼作簡單介紹, 先介紹第一個function:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
def prepare_list_and_dict(img_path):
dict_to_save = {}
img_list = []
path = img_path
files = os.listdir(path) #files = ['training_data'] #list
#print(files)
for file in files:
filepath = path+ "/" + file #filepath = all/training_data #string
#print("filepath:", filepath)
filenames = os.listdir(filepath) #filenames = ['1','2','3',...'120']
#print("filenames:", filenames)
for filename in filenames:
img_filename = filepath + "/" + filename #img_filename = all/training_data/1 #string
#print("img_filenames:", img_filename)
img_paths = os.listdir(img_filename) #img_paths = ['IMG_20190719_123338.jpg'...]
#print("img_paths:", img_paths)
for img_path in img_paths:
pic_path = img_filename + "/" + img_path
img_name = pic_path #all/training_data/1/IMG_20190719_123338.jpg
#print("img_name:", img_name)
img_label = int(filename) #filename = 1~120
img_list.append(img_name)
dict_to_save[img_name] = img_label
#print("dict_to_save:", dict_to_save)
return img_list, dict_to_save
我們要把img_path路徑輸入函數中
然後把這一層的files全部找出來(只有training_data一個)
再把裡面所有的files逐個列出裡面的檔案
原本這樣的設計是為了把120種signs分為5個files而寫的
現在合併為1個file所以這樣寫有些傻(for裡面的files只有1個file)
但程序仍然是正常的
1
2
3
4
5
6
7
8
9
def prepare_list_and_dict(img_path):
files = os.listdir(path) #files = ['training_data']
for file in files:
filepath = path+ "/" + file #filepath = all/training_data
filenames = os.listdir(filepath) #filenames = ['1','2','3',...'120']
for filename in filenames:
img_filename = filepath + "/" + filename #img_filename = all/training_data/1 #string
img_paths = os.listdir(img_filename) #img_paths = ['IMG_20190719_123338.jpg'...]
dict_to_save[img_name] = img_label #dict_to_save = {'IMG_20190719_123338.jpg':1, ....} <img src="/img/train_path2.png" width="70%"> <img src="/img/train_path3.png" width="70%">
程序旁已寫上#解釋如何得出相片的路徑及file的名稱
相片名稱是讀取data的索引, 而file名稱則是label
合併則成為dict
==========================TWO==========================
第二個function是把第一個function準備好的list讀取數據出來:
return x,y 表示x_data和y_label已準備好
try…except…這種寫法是當程序出現問題是如何處理
我們選擇pass, 即是不處理繼續運行
在相片的file裡面, 常常有一些不是圖片的檔案在裡面(因為macbook會產生很多.xxx命名的file)
這樣讀取圖片時只要在100多個files裡面其中一個出錯, 程序便會立即停止
1
2
3
4
5
6
7
8
9
10
11
12
13
def prepare_data(img_list, dict_names):
x = [] # images as arrays
y = [] # labels
img_width = 150
img_height = 150
for image in img_list: #cv2.imread(image)是用cv2讀取圖片, image是路徑, 返回一串data, 以list形式儲存在x中
try:
x.append(cv2.resize(cv2.imread(image), (img_width, img_height), interpolation=cv2.INTER_CUBIC))
label = int(dict_names[image])
y.append(label)
except:
pass
return x, y
==========================THREE==========================
第三個和第四個function是生成器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def data_generator(data, targets, batch_size): #x=np.array(x_train), y=y_train
batches = (len(data) + batch_size - 1)//batch_size #假設len=100, batch=10, (100+10-1)//10 = 10
while(True):
for i in range(batches): #把data分成n=batches份區間
X = data[i*batch_size : (i+1)*batch_size] #每一區間內的data讀取
Y = targets[i*batch_size : (i+1)*batch_size] #每一區間內的label讀取
yield (X, Y)
def val_generator(data, targets, batch_size):
batches = (len(data) + batch_size - 1)//batch_size
while(True):
for i in range(batches):
X = data[i*batch_size : (i+1)*batch_size]
Y = targets[i*batch_size : (i+1)*batch_size]
yield (X, Y)
batches = (len(data) + batch_size - 1)//batch_size
是因為data和batch_size相除有小數時需要自動進位(不是4捨5入, 4.1也當作5)
而batches恰好為整數時則不變
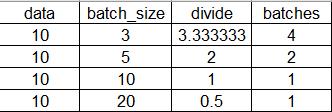
一個相同功能的寫法是:
1
2
3
4
if len(data) % batch_size !=0:
batches = int(len(data)/batch_size) +1 #eg. batches = int(10/3) + 1 = 3 +1
else:
batches = int(len(data)/batch_size) #eg. batches = int(10/5) = 2
==========================FOUR==========================
train_test_split是把相片集自動隨機分為2部分
為了把一個相片集分為3部分, 首先把相片集分為mid及val, 再把mid分為train和test
這樣便得到了training_data, validation_data及test_data
比例是任意設定的
這裡的訓練技巧是稱為交叉驗證的方法, 即第1次使用隨機的5分3作為training_data
下次則選擇任意隨機的5分3, 最終使用多次後相當於把整個data_set都能用作training
不用特意保留5分2的相片用作validation及test, 相當於把相片集的效益最大化
但交叉驗證也不是只有好處, 詳情自行查詢
1
2
3
'''train_test_split, train:val:test = 3:1:1'''
x_mid, x_val, y_mid, y_val = train_test_split(x,y, test_size=0.2) #mid:val = 4:1
x_train,x_test,y_train,y_test = train_test_split(x_mid,y_mid,test_size=0.25) #train:test = 3:1
==========================FINAL==========================
設定one-hot, CNN這些常規操作之後是數據增強, 生成器及訓練model
3個function是一起的, 先設計好數據增強的參數
然後套用在生成器的data上, 最後model.fit_generator
最後的只是顯示訓練record, model.save, model.evalutate, show picture等等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
train_datagen = ImageDataGenerator(
zca_whitening=True,
#rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
channel_shift_range=10,
horizontal_flip=False)
val_datagen = ImageDataGenerator(
zca_whitening=True,
#rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
channel_shift_range=10,
horizontal_flip=False)
train_generator = data_generator(np.array(x_train), y_train, batch_size=batch_size)
validation_generator = val_generator(np.array(x_val), y_val, batch_size=batch_size)
visualize_acc_loss = model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size,
callbacks=[csv_logger]) #callbacks可以建立csv檔
其他部分和mnist和cifar10的概念差不多, 可以自行研究
練習
(1)交叉驗證(cross_validation)是什麼?
(2)生成器(generator)是什麼?
(3)try…except的例子?
(4)CNN model的建構流程?何時用BatchNormalization?在Activation前還是後?
(5)CNN model的Dense何時用Dropout?Dropout相當於什麼功能?
(6)model如何保存?保存後如何再次使用?
(7)model.fit的val_acc和model.evaluate的acc有什麼分別?為什麼要做兩次?
(8)one-hot是否必須?